数据库 Database
Oracle DB2 MySQL
Oracle 11g 从系统层面误删了 system 表空间的数据文件,出现故障
误删system表空间数据文件引发的故障及ora-01552的处理过程分享
误操作过程(引发故障的操作步骤)
2026年1月21日下午4:40左右,误操作的过程
alter tablespace SYSTEM add datafile '/u01/app/oracle/oradata/hiatmpdb/datafile/undotbs02_01.dbf' size 5G;然后新建了
alter tablespace UNDOTBS2 add datafile '/u01/app/racle/oradata/hiatmpdb/datafile/undotbs02_02.dbf' size 5G通过查询表利用率恢复后
进入目录删除了表文件
cd /u01/app/oracle/oradata/hiatmpdb/datafile/
rm -rf undotbs02_01.dbf
然后1月22日早上通过日志查看数据库出现问题时间是21日晚上21:00
[捏把汗,生产环境用 rm -fr,也是胆子大啊]
=============================================================
处理经过
到现场查看环境:Linux+Oracle 11g,没有备份,非归档,数据库已经重启过
当前面临的核心问题:
手动删除了属于 SYSTEM 表空间的数据文件(尽管命名为 undotbs...,但第一条命令将其加入了 SYSTEM 表空间)。由于 SYSTEM 表空间是数据库的“大脑”,一旦其文件损坏或丢失,数据库通常会宕机或无法正常启动。
现状评估 / 致命错误:本意可能是想操作回滚表空间(UNDO),但第一条命令误将文件加到了 SYSTEM 表空间。这是非常严峻的情况:目前SYSTEM 表空间数据文件从系统层面被删除 + 无备份 + 非归档模式。
在非归档模式下,一旦文件被 rm 且数据库重启,通常意味着该文件在删除到重启之间的所有数据变化已经无法通过日志追回。由于该文件属于 SYSTEM 表空间(存放着数据字典),它的缺失会导致数据库无法验证元数据,从而无法 OPEN。
故障表现:由于操作系统层面的 rm 删除了文件,而数据库进程(DBWR)在尝试写入该文件时发现句柄失效,导致 21:00 左右数据库出现异常或崩溃。
过程:
第一步:尝试“欺骗”恢复(重建空文件)
由于该文件是昨天下午刚创建的,如果从创建到晚上 21:00 之间,该文件内没有写入关键的系统对象,我们尝试通过重建一个空文件来让数据库认为“文件还在”。
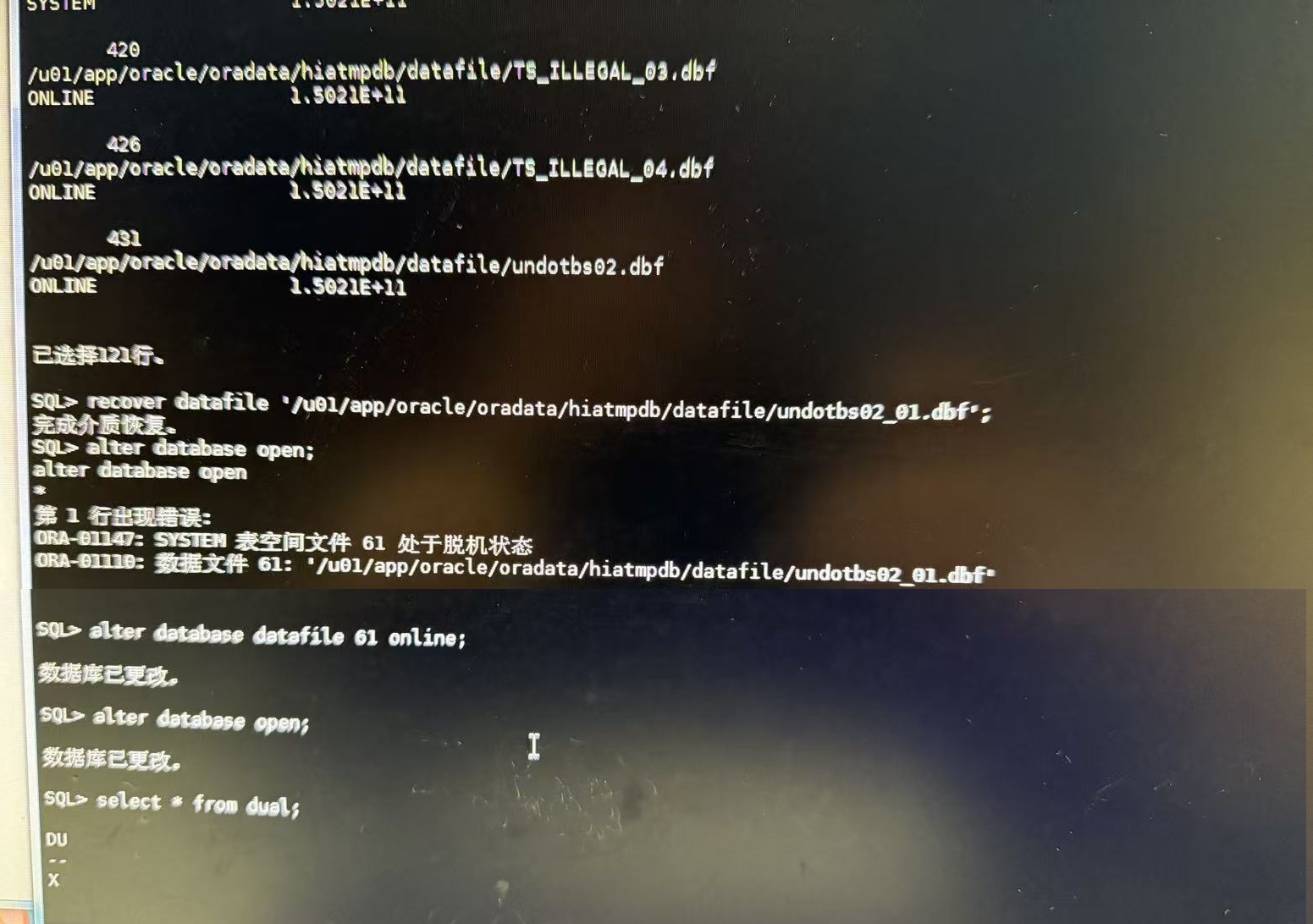
ALTER DATABASE CREATE DATAFILE '/u01/app/oracle/oradata/hiatmpdb/datafile/undotbs02_01.dbf';
RECOVER DATAFILE '/u01/app/oracle/oradata/hiatmpdb/datafile/undotbs02_01.dbf';
(说明2条语句本案例执行无报错,提示成功。第2条语句如果当它提示输入日志时,尝试 CANCEL。)
同步观察查看alert.log (tail -f )
第二步:
查看表空间状态
发现 /u01/app/oracle/oradata/hiatmpdb/datafile/undotbs02_01.dbf (file# 61)是SYSOFF 状态
于是尝试使文件online
alter database datafile 61 online;
执行成功
alter database open;
执行成功
------------------------------------------------------------------------------------
按常理,此时数据库应该就应该恢复正常,但没有
用 pl/sql 连库,可以读取表,读都是正常的,但不能写入,写入就提示错误
【MQ也有错误日志(ORA-01552: cannot use system rollback segment for non-system tablespace 不能使用系统回滚段)】
观察alert.log,里面有ORA-0001的错误
查看参数
SQL> show parameter undo
输出结果是不正常的,如下
undo_management,string,MANUAL
undo_retention,integer,900
undo_tablespace,string,SYSTEM
于是停库,启动到mount状态,修改
ALTER SYSTEM SET undo_management='AUTO' SCOPE=SPFILE; -- 修改回滚管理模式为自动(需重启生效)
ALTER SYSTEM SET undo_tablespace='UNDOTBS1' SCOPE=BOTH; -- 修改回滚表空间为专门的 UNDO 表空间
(通过sql查询,已有 UNDOTBS1,-- SELECT tablespace_name, status FROM dba_tablespaces WHERE contents = 'UNDO';)
修改以后,查看结果:
undo_management,string,AUTO ----数据库默认为自动管理
undo_retention,integer,900 ----撤销数据保留时长(秒),默认 15 分钟
undo_tablespace,string,UNDOTBS1 ----当前正在使用的回滚表空间名
再执行
alter database open;
执行成功
此时观察业务表已经有正常数据写入,至此数据库可读可写,恢复正常
用户马上做了expdp 的全库备份
至此,操作完毕
=====================================================================
在 Oracle 中,回滚段(Undo)分为两种:
系统回滚段 (System Rollback Segment):专门给 SYSTEM 表空间里的操作使用。
非系统回滚段 (Non-System Rollback Segment):给普通表空间(如 USERS, DATA, INDEX 等)里的操作使用。
故障逻辑链:
设置是 MANUAL 模式,且没有指定有效的 UNDO 表空间。
Oracle 此时被强行切换到了“手动回滚模式”,它发现没有可用的普通回滚段,于是试图用 SYSTEM 表空间里的“系统回滚段”来处理普通表的增删改操作。
Oracle 规则禁止这样做:系统回滚段不允许用于非系统表空间的事务,为了防止 SYSTEM 表空间被撑爆或损坏,系统直接抛出 ORA-01552 并中断操作。
=====================================================================
补充 A:数据库尚未关闭(文件句柄可能还在内存中)
如果数据库还没重启,仍有机会从内存中找回文件。
查找文件句柄:执行 lsof | grep undotbs02_01.dbf。
恢复文件:如果能看到类似 (deleted) 的条目,记录下该进程的 PID 和文件描述符 FD。
直接复制回原位:cp /proc/$PID/fd/$FD /u01/app/oracle/oradata/hiatmpdb/datafile/undotbs02_01.dbf。
同步数据:进入 SQLPlus 执行 alter database datafile '...path...' online;
补充 B:为什么 21:00 才报错?
这是典型的 Lazy Writing(延迟写入) 现象。
4:40 执行 alter tablespace 时,Oracle 只是在控制文件和数据字典里注册了该文件。
由于是新加的文件,里面没有存量数据,数据库在低负载时不会立即频繁读写它。
到了 21:00,可能发生了 Checkpoint(检查点)/ 全库备份 / 系统表空间自动扩展,DBWn 进程尝试向该文件写入数据,发现物理文件不存在,于是触发了实例崩溃(Instance Crash)。
补充 C:终极手段(修改隐藏参数跳过一致性检查)
如果上述步骤失败,报 ORA-01110 或 ORA-01113,只能通过隐藏参数强行打开数据库。
警告: 此操作可能导致数据字典损坏,仅用于将数据导出(expdp)备份,不建议长期运行
创建 PFILE(从当前 SPFILE):
CREATE PFILE='/tmp/pfile_recover.ora' FROM SPFILE;
编辑该 PFILE 文件: 在文件中添加以下三行:
_allow_resetlogs_corruption = true
_allow_terminal_recovery_with_data_loss = true
_corrupted_rollback_segments = true
尝试使用该 PFILE 启动:
SHUTDOWN IMMEDIATE;
STARTUP MOUNT PFILE='/tmp/pfile_recover.ora';
-- 尝试强制打开
ALTER DATABASE OPEN;
===========================================================================
RECOVER DATAFILE '/u01/app/oracle/oradata/hiatmpdb/datafile/undotbs02_01.dbf';
执行这个命令时,数据库正试图进行介质恢复(Media Recovery)。
即使现在处于非归档模式且文件是新创建的空文件,Oracle 的内核依然会按照一套严密的逻辑来尝试修复它。
以下是执行该命令时,数据库内部发生的具体动作:
1. 检查控制文件(Control File)Oracle 首先读取控制文件,查看该数据文件的元数据信息。它会查找该文件的 Checkpoint SCN(检查点系统更改号)。
由于之前执行了 CREATE DATAFILE,控制文件里记录的该文件 SCN 通常是 0 或者是一个非常小的值,而数据库中其他文件(如 system01.dbf)的 SCN 已经是昨晚 21:00 之后的值了。
2. 确定恢复起点数据库发现文件头部的 SCN 与控制文件要求的不一致。
它会计算出从哪一个 Redo Log(重做日志) 开始才能把这个文件“拉齐”到当前状态。
它会寻找包含该文件“创建记录”或“最后一次写入记录”的那个日志序列号(Sequence Number)。
3. 应用重做日志(Redo Apply)这是最核心的动作。如果日志存在,数据库会:
读取(Read):从联机重做日志或归档日志中读取更改向量(Change Vectors)。
应用(Apply):将这些更改重新写入到 /u01/app/oracle/oradata/hiatmpdb/datafile/undotbs02_01.dbf 这个空文件中。
验证(Verify):每应用一条,SCN 就会增加,直到与当前数据库的一致性 SCN 对齐。
